帮助企业利用多模态数据训练AI模型,Activeloop获1100万美元A轮融资
近日,据海外媒体报道,来自美国的人工智能创新公司Activeloop宣布已完成1100万美元的A轮融资,投资者包括Streamlined Ventures、Y Combinator、Samsung Next(三星集团旗下的创业加速部门)等投资机构。
Activeloop的主要为人工智能项目提供特定的数据库服务,尽管市场上已经有不少近似产品,但是Activeloop找到了其中一个利基市场:其系统可以解决企业当今面临的最大挑战之一,即利用非结构化的多模态数据来训练人工智能模型。据该公司称,这项被称为Deep Lake的技术允许技术团队以比市场上其他近似产品低75%的成本开发人工智能应用程序,同时将工程技术团队的生产力提高5倍。
Activeloop的这项技术非常重要,因为越来越多的企业正在寻找方法,将企业复杂的数据集用于针对不同用例的人工智能应用程序。
今天,要训练高性能的基础人工智能模型涉及处理PB(petabyte)级别的非结构化数据,包括文本、音频和视频等。训练任务通常需要团队从混乱的数据孤岛中识别相关的数据集,并需要使用不同的存储和检索技术。这需要工程师进行大量的编码和集成,并可能增加项目成本。
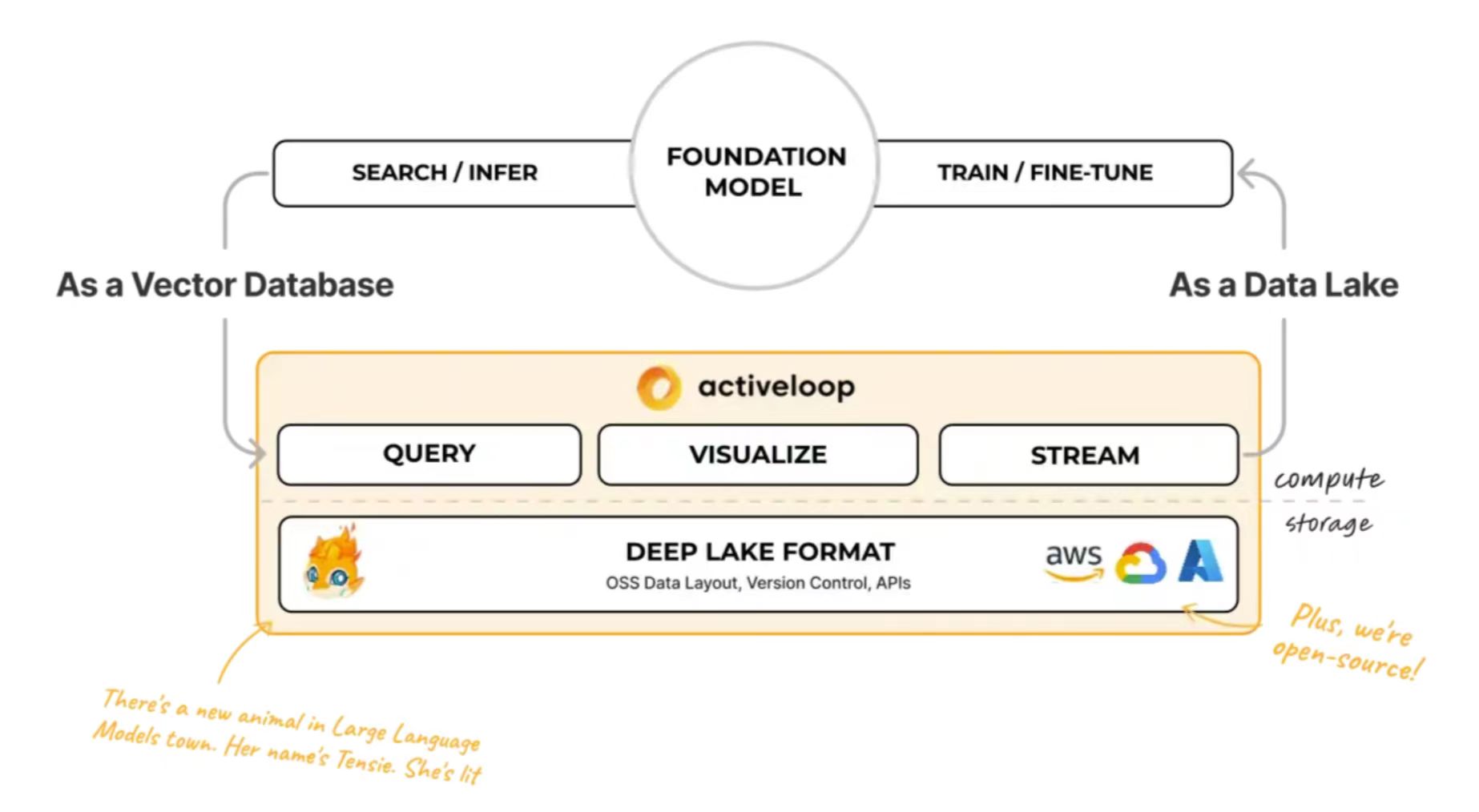
Activeloop的Deep Lake以机器学习的形式存储复杂的数据,如图像、视频和注释等原生数学表示(张量,tensors),并促进这些张量的引流到类似SQL的张量查询语言,这是一种浏览器内可视化引擎或深度学习框架(如PyTorch和TensorFlow)。这就为开发人员提供了一个平台,从过滤和搜索多模态数据,到跟踪和比较其版本,再到针对不同用例的训练模型。
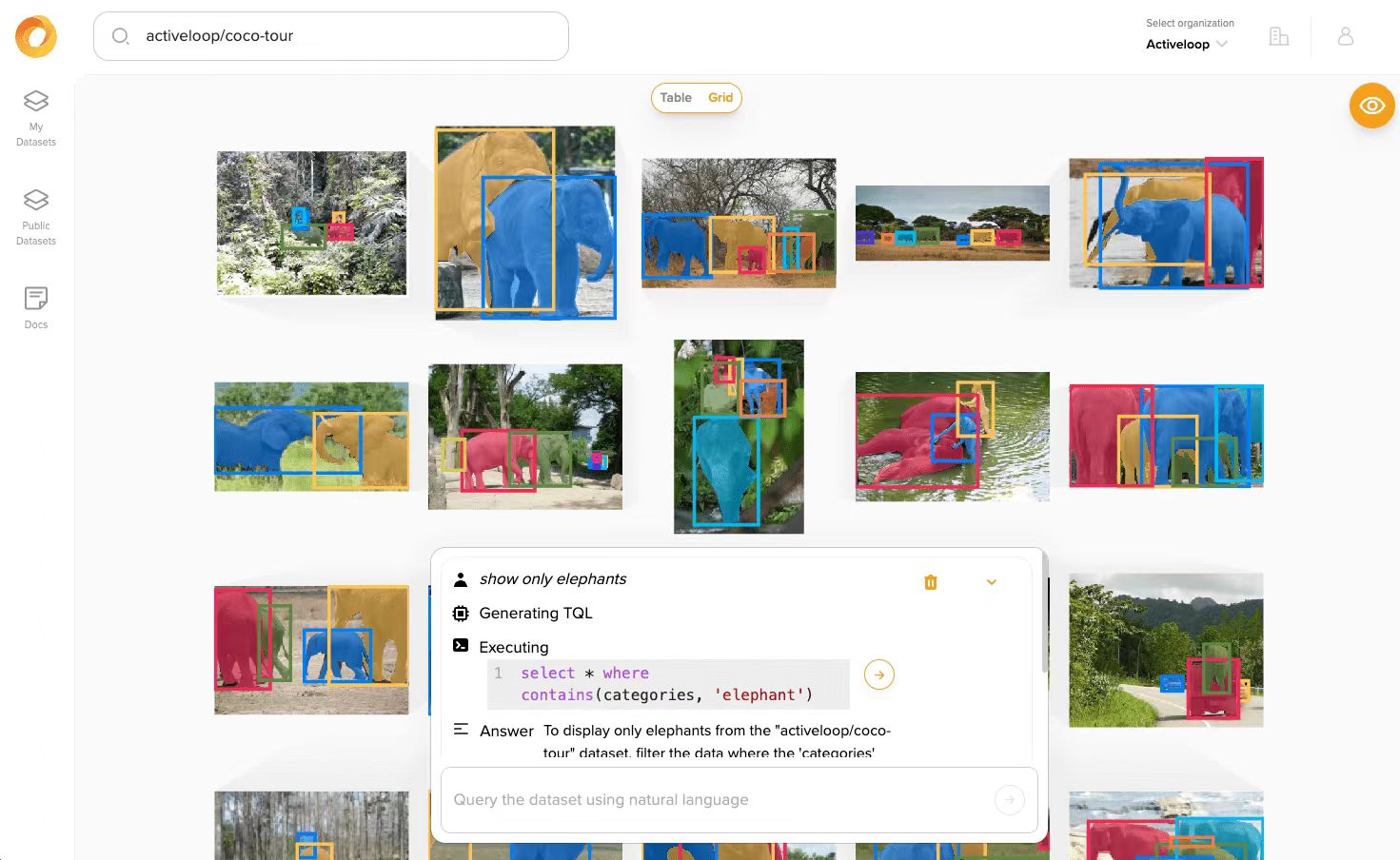
Activeloop公司表示,Deep Lake提供了普通数据湖的所有优点(例如从数据孤岛中摄取多模态数据),但其突出之处是将这些数据全部转换为张量格式,这是深度学习算法期望的输入。张量整齐地存储在基于云的对象存储或本地存储中,然后从云无缝地流入到图形处理单元(GPU)中进行训练,只需传递足够的数据来进行计算,即可充分利用。以前处理大型数据集的方法需要批量复制数据,这会导致GPU的闲置。
公司创始人Davit Buniatyan表示,他从2018年开始研究Activeloop和Deep Lake技术,当时他在普林斯顿神经科学实验室(Princeton Neuroscience Lab)面临着存储和预处理数千张高分辨率小白鼠大脑扫描图的挑战。从那时起,Activeloop公司开发了两大类核心数据库功能:开源数据库和专有数据库。
他补充道,开源方面包括数据集格式、版本控制以及为流(streaming)和查询设计的大量API,以及其他功能。而在专有方面包括了高级可视化工具、知识检索和高性能流媒体引擎,这些都增强了他们产品的整体功能和吸引力。
虽然他没有透露Activeloop正在合作的确切客户数量,但他确实指出,到目前为止,这个开源项目已经被下载了100多万次,并被生物制药、生命科学、医疗技术、汽车和法律等高度监管行业的财富500强公司所使用。例如,Activeloop的其中一个客户:拜耳放射学公司(Bayer Radiology)就在使用Deep Lake将不同的数据模式统一到一个存储解决方案中,简化了数据预处理时间,并启用了新的“与X射线聊天”(chat with X-rays)功能,允许数据科学家以自然语言查询扫描结果。
随着新融资的完成,Activeloop计划创建自己的企业级产品,并将更多客户吸引到AI数据库中,使企业能够轻松组织复杂的非结构化数据并检索知识。Davit Buniatyan提到,将发布的Deep Lake v4是一个关键的发展,它具有更快的并发输入输出、用于训练模型的最快的流数据加载器、完整的可复制数据序列和外部数据源集成。
最终,他希望这项技术能够为企业节省数百万美元用于数据组织和检索的内部解决方案,并使工程师不必做大量的手工工作和样板编码,从而提高他们的工作效率。
延伸阅读:
- 企业级人工智能初创公司Writer发布多模态AI模型,提升企业对图形图像数据的分析提炼
- 人工智能计算基础设施Recogni获超1亿美元C轮融资,提升下一代AI推理解决方案的性能和效率
- 为企业提供生成式AI服务,谷歌发布企业级人工智能产品Gemini for Workspace
- 为企业营销活动提供人工智能和流程自动化能力,网络营销服务商Ignition融资800万美元
- 估值20亿美元,法国人工智能公司Mistral AI融资4.5亿欧元
Powered by Froala Editor