
微软发布Azure AI Speech,方便创建可实时交互的数字化身
近日,据海外媒体报道,微软公司发布了Azure AI Speech的公开预览版,该技术允许用户通过文本输入创建会说话的数字化身(avatar)视频,并使用人类图像构建实时交互式机器人。
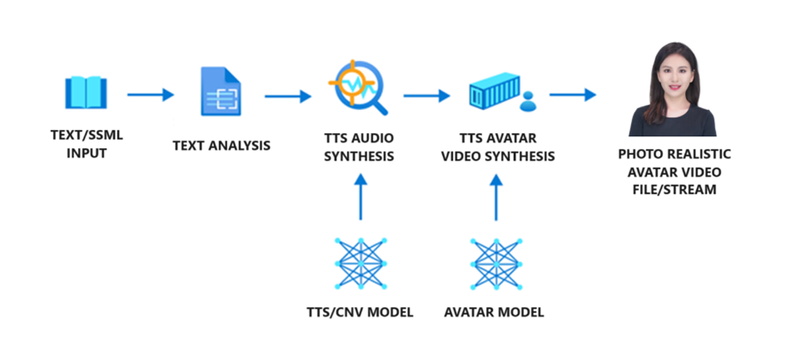
Azure AI Speech在最近的一篇博客文章中表示,文本到语音数字化身(text-to-speech avatar)是一项具有视觉功能的新功能,使用户能够生成2D的逼真数字化身且具有说话能力的合成视频。
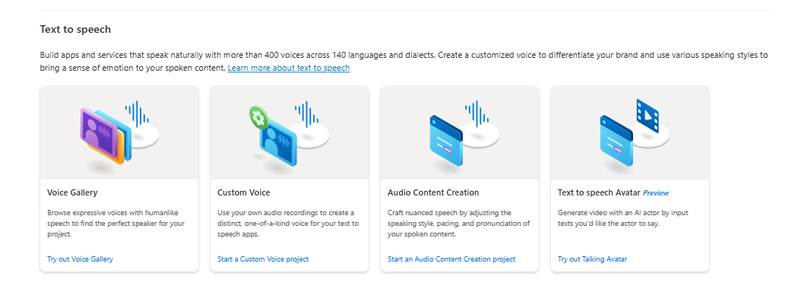
该博客文章提到,这个数字化身模型使用基于人类视频记录样本的深度神经网络进行训练,而声音则由文本到语音的语音模型提供。同时,该文章也提到,这种文字转语音的数字化身可用于培训视频、产品介绍、广告、虚拟销售代理、人工智能教师、虚拟人力资源助理以及其他应用和用例。
另外,该博客文章还提到,创建数字化身的主要原因之一是简化视频内容的创作。传统的方法需要大量的时间和预算来拍摄和编辑。有了文字转语音的支持,用户可以简单地输入文字,根据自己的需要创建视频。

根据该博客文章介绍,Azure OpenAI服务和神经文本到语音(neural text-to-speech)的发布使交互式对话更加自然。文本到语音的数字化身使用户能够创建引人入胜的数字交互。Azure AI Speech提供两种不同的文本到语音数字化身功能。预构建的文本到语音数字化身在Azure上提供了开箱即用的产品,允许客户从各种视频内容或交互式应用程序中进行选择。而自定义的文本到语音的数字化身功能使客户能够通过上传自己的视频记录来为他们的产品或品牌创建个性化的数字化身。
延伸阅读:
- 微软发布面向销售场景的Copilot,将与微软其他产品进行深度整合
- 微软Xbox和Inworld AI联合推出基于AI的游戏开发工具,重点或是助力开发出更具游戏适应性的NPC
- 微软发布AutoGen开源框架,简化大语言模型工作流的编排、优化和自动化
- 微软计划将Copilot AI集成入现场工作平台,为一线工作人员简化工作流程
- 微软发布Chat API,允许在聊天对话中插入广告
Powered by Froala Editor







