
斯坦福大学和Google DeepMind联合发布RT-Sketch模型,用草图作为机器人系统的输入指令
随着在语言模型和视觉模型方面的最新进展,旨在帮助在创建能够遵循文本描述或图像指令的机器人系统方面也取得了巨大进展。然而,机器人系统在基于语言和图像的指令所能完成的任务是有限的。
近日,由斯坦福大学(Stanford University)和Google DeepMind的一项最新研究使用草图作为机器人的输入指令。草图具有丰富的空间信息,可以帮助机器人执行任务,而不会被杂乱的真实图像或自然语言指令的模糊性所迷惑。
研究人员发布了RT-Sketch,这是一种使用草图来控制机器人的模型。在正常情况下,机器人的表现与语言或图像指令输入条件下的智能体相当。但是在语言和图像信息不足的情况下,它的表现更好。
虽然语言是目标指定的一种直观方式,但是当任务需要精确的操作时,例如将对象放置在特定的位置,语言这种方式可能会变得不方便。
另一方面,图像可以有效地详细描述机器人的期望目标。然而,获取目标图像通常是不可能的,并且预先录制的目标图像可能包含太多细节。因此,在目标图像上训练的模型可能会过度拟合其训练数据,而无法将其能力推广到其他环境。
斯坦福大学的博士生Priya Sundaresan表示,对草图进行调节的最初想法实际上源于早期的头脑风暴,即我们如何使机器人能够理解组装手册,比如宜家家具的原理图,并进行必要的操作。对于这种需要空间精确的任务,语言通常是非常模糊的,而且事先无法获得所需场景的图像。
因此,研究团队决定使用草图。因为草图的数据最小,易于收集,并且信息丰富。一方面,草图提供了难以用自然语言指令表达的空间信息。另一方面,草图可以提供所需空间安排的具体细节,而不需要像在图像中那样保留像素级细节。同时,草图可以帮助模型学习分辨哪些对象与任务相关,从而产生更加通用的功能。
Priya Sundaresan表示,我们认为草图是人类向机器人指定目标的更方便、更有表现力的方式的基石。
RT-Sketch是许多使用transformers的新型机器人系统之一,transformers是用于大语言模型的深度学习架构。RT-Sketch基于Robotics Transformer 1 (RT-1),这是一种由DeepMind开发的模型,可以将语言指令作为输入,并为机器人生成命令。RT-Sketch修改了架构,将自然语言输入替换为视觉目标,包括草图和图像。
为了训练这个模型,研究人员使用了RT-1数据集,其中包括8万份VR(虚拟现实)远程操作演示的记录,比如移动和操纵物体,打开和关闭橱柜等。然而,首先,他们必须根据演示创建草图。为此,他们选择了500个训练示例,并从最终的视频帧中创建了手绘草图。然后,他们使用这些草图和相应的视频帧以及其他图像转生成草图(image-to-sketch)的示例来训练生成对抗网络(GAN),GAN可以从图像中创建草图。
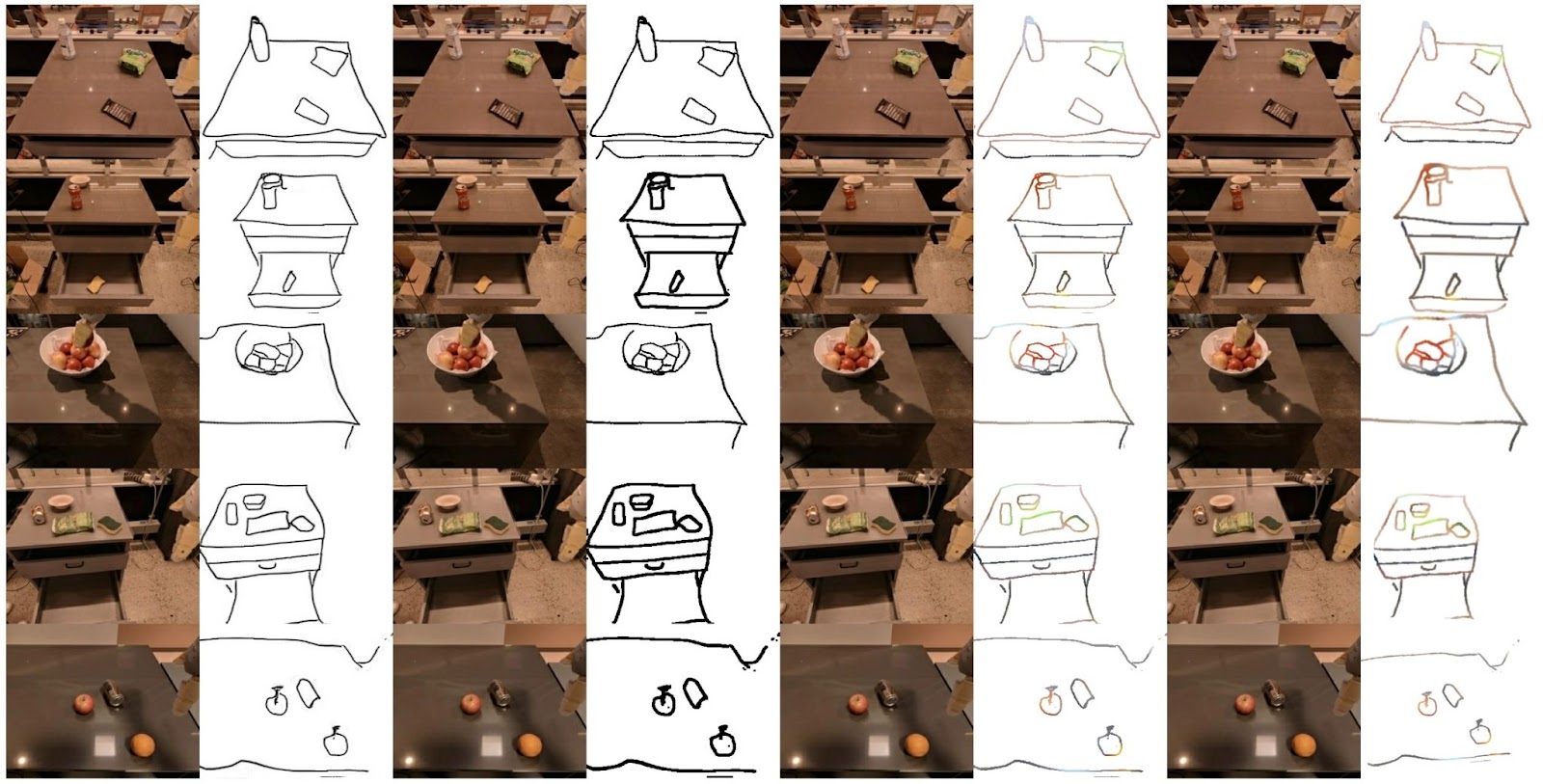
研究人员使用GAN网络创建目标草图来训练RT-Sketch模型。他们还用不同的色彩空间和仿射变换来增强这些生成的草图,以模拟手绘草图的变化。然后在原始记录和目标状态的草图上训练RT-Sketch模型。训练后的模型获取场景图像和所需物体排列的粗略草图。作为响应,它能够生成一系列机器人命令来达到预期的目标。
Priya Sundaresan表示,RT-Sketch在空间任务中很有用,在这些任务中,用文字描述预期目标比用草图描述要花更长的时间,或者在无法获得目标图像的情况下。
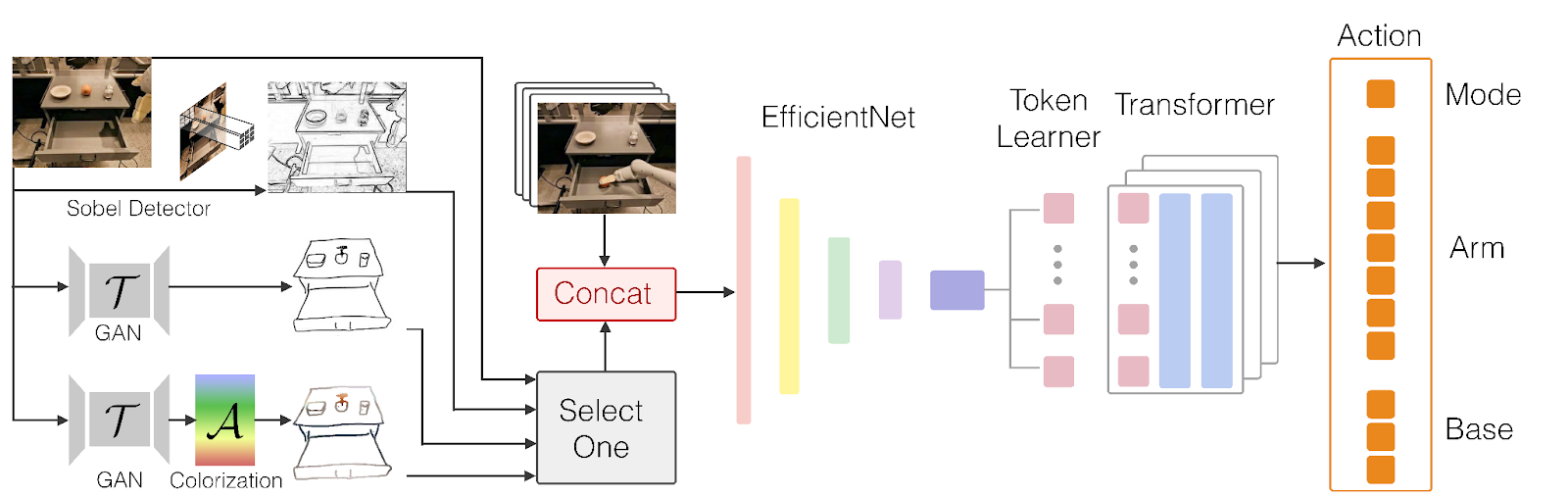
RT-Sketch接受视觉指令,并为机器人生成动作命令
例如,如果你想摆一张餐桌,像“把餐具放在盘子旁边”这样的语言指令可能会因为多套刀叉和许多可能的放置而变得模棱两可。使用语言条件模型需要对模型进行多次交互和修正。与此同时,要想获得想要的场景的图像,就需要提前解决任务。使用RT-Sketch,你可以提供一个快速绘制的草图,说明你希望如何排列对象。
Priya Sundaresan表示,RT-Sketch还可以应用于移动机器人在新空间中安排或打开物品和家具的场景,或者任何长期任务,如多步骤的折叠衣服,其中草图可以帮助直观地传达一步一步的子目标。
延伸阅读:
- 海外媒体报道,亚马逊产业基金将加大对结合AI和机器人的创新项目的投资
- 人工智能人形机器人公司1X融资1亿美元,曾获OpenAI投资
- 加州大学伯克利分校发布多功能控制系统,利用生成式AI让人形机器人更好地适应未知环境
- 当人工智能结合工业机器人,英伟达旗下投资部门领投Machina Labs最新的3200万美元融资
Powered by Froala Editor







