
谷歌研究院发布视频生成大语言模型VideoPoet
近日,据海外媒体报道,谷歌(Google)公司发布了名为VideoPoet的新的大语言模型,该模型由谷歌研究院(Google Research)的31名研究人员组成的团队专为各种视频生成任务而设计。
谷歌的研究人员在预审研究论文中提到,大多数的现有模型采用基于扩散的方法,这些方法通常被认为是当前视频生成中表现最好的方法。这些视频模型通常从一个预训练的图像模型开始,比如稳定扩散,它可以为单个帧产生高保真图像,然后对模型进行微调,以提高视频帧之间的时间一致性。
相比之下,谷歌的研究团队没有使用基于流行(且有争议的)Stable Diffusion开源图像/视频生成的扩散模型,而是使用大语言模型,这是一种基于transformer架构的不同类型的AI模型,通常用于文本和代码生成,例如ChatGPT、Claude 2或Llama 2。但谷歌研究团队没有训练它用来生成文本和代码,而是训练它来生成视频。
为此,谷歌研究团队对来自“公共互联网和其他来源”的2.7亿个视频和超过10亿文本和图像对VideoPoet LLM进行了大量“预训练”。具体来说,将这些数据转化为文本嵌入、视觉标记和音频标记,这是人工智能模型的“条件”。
不仅如此,谷歌研究团队还指出,他们的大语言模型视频生成方法实际上可以实现更长、更高质量的视频片段,消除了当前基于扩散的视频生成人工智能的一些限制和问题。在后者的实践中,视频中主体的运动往往在几帧后就会崩溃或出现故障。
谷歌研究团队中的Dan Kondratyuk和David Ross表示,目前视频生成的瓶颈之一是产生连贯的大动作的能力。在许多情况下,即使是目前领先的模型,也会产生小的运动,或者在产生较大的运动时,会出现明显的瑕疵。

上图的GIF动画展示了谷歌的VideoPoet如何使静态图像实现动画效果
但是根据研究人员在网上发布的例子,VideoPoet可以在16帧的长视频中产生更大、更一致的动作。它还具备更广泛的功能,包括模拟不同的摄像机运动,不同的视觉和美学风格,甚至生成新的音频来匹配给定的视频剪辑。它还能够处理一系列输入,包括文本、图像和视频,以作为提示。
将所有这些视频生成功能集成到一个大语言模型中,VideoPoet消除了对多个专用组件的需求,为视频创建提供了无缝的一体化解决方案。
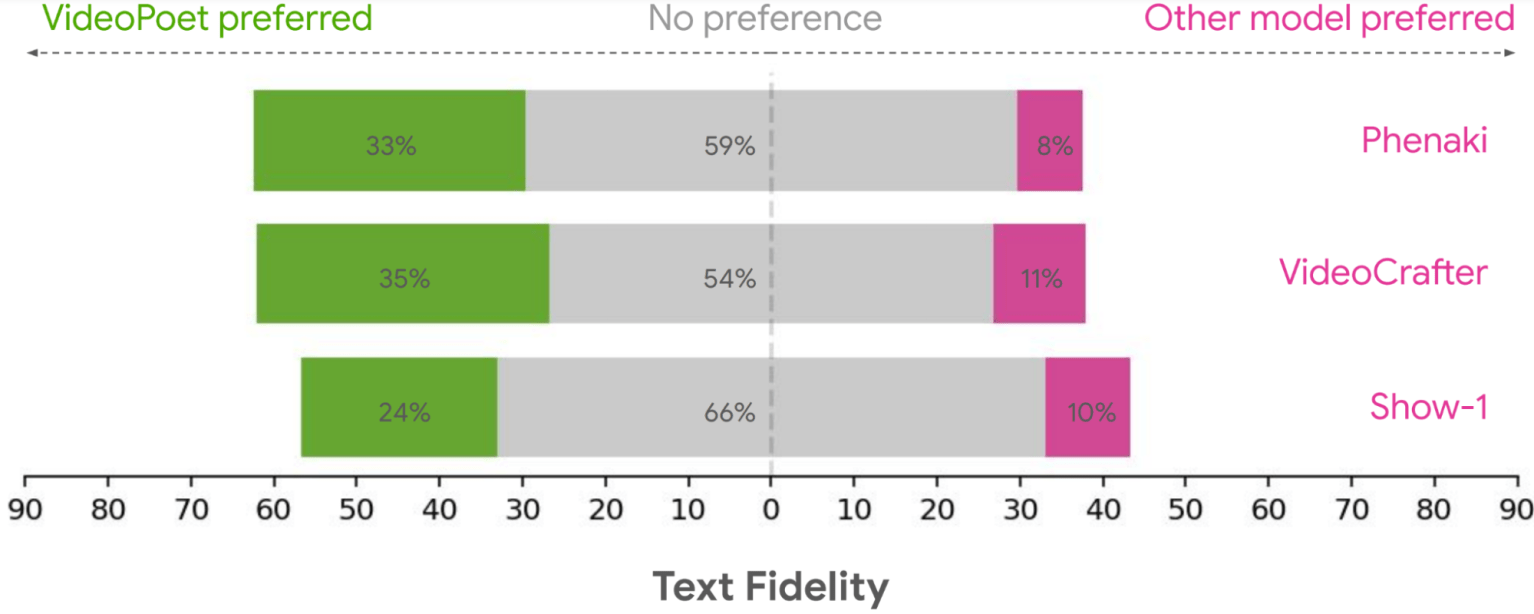
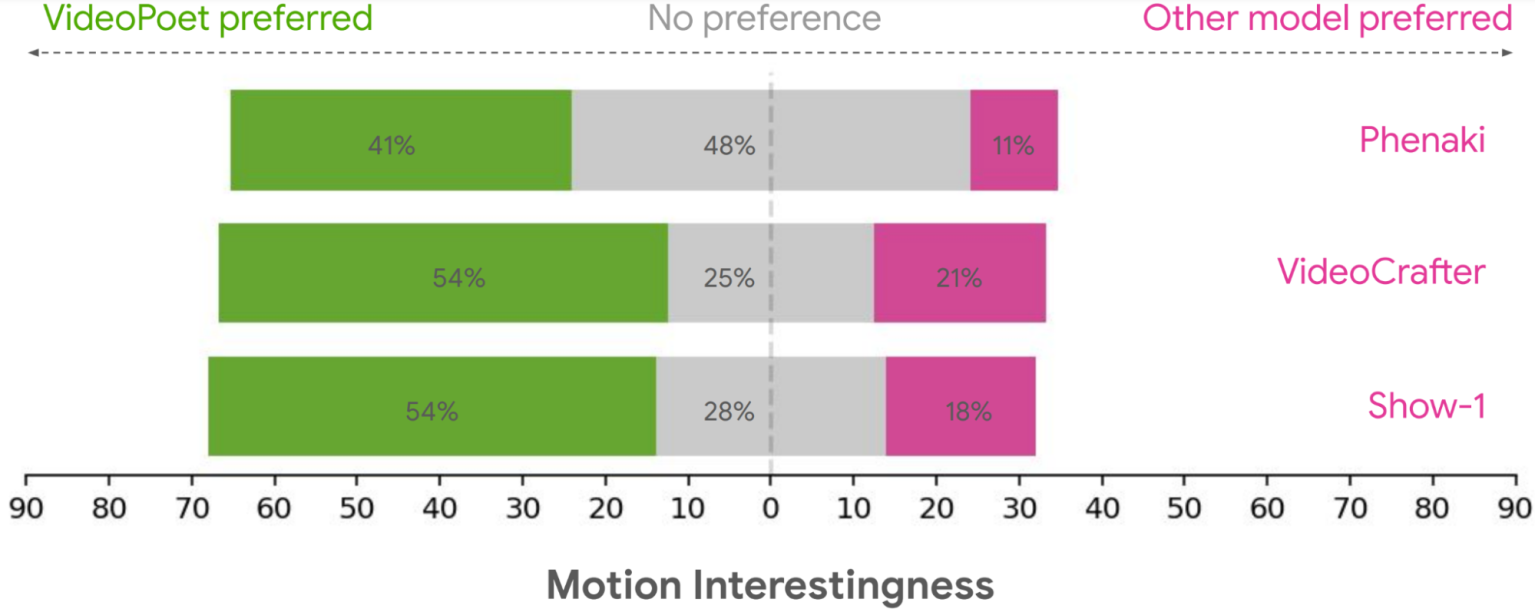
研究人员将由VideoPoet生成的视频片段展示给未指定数量的“人类评分者”,以及由视频生成扩散模型Source-1、VideoCrafter和Phenaki生成的视频片段,同时并排显示两个片段。人类评分者在很大程度上认为VideoPoet的视频剪辑在他们眼中是优越的。
正如谷歌研究博客文章所总结的那样:“平均而言,人们从VideoPoet中选择了24-35%的示例,比竞争对手的模型更好,而竞争对手的模型只有8-11%。”评分者更喜欢来自VideoPoet的例子,因为它们的视频动作更有趣。
Google Research将VideoPoet定制为默认制作纵向视频,即“垂直视频”,以迎合因Snap和TikTok而流行的移动视频市场。

由Google Research的VideoPoet视频生成大语言模型创建的垂直视频示例
展望未来,Google Research设想扩展VideoPoet的功能,以支持“任意到任意”的生成任务,如文本到音频和音频到视频,进一步推动视频和音频生成的可能性。
不过,目前VideoPoet还不能供公众使用。
延伸阅读:
Powered by Froala Editor







