DevTalk开发者沙龙 | 纸上绝知创始人张哲:看好计算机视觉技术在智能学习硬件上的应用,但依然面临诸多巨大挑战
2021年12月18日下午,由映魅咨询IMConsultancy主办的DevTalk第4期沙龙在上海举办。这次沙龙的主题围绕着计算机视觉技术在教育学习产品场景中的设计展开,分别邀请了在相关领域的技术专家、公司创始人等进行了专业分享。
在本次沙龙中,我们邀请了纸上绝知的创始人张哲,他曾经在百度从事人工智能相关的实践工作,并在创业过程中也将计算机视觉技术应用到和客户的软硬件教育项目中,具有非常丰富的技术经验和对教育学习场景特点的理解。

以下是张哲的分享内容精要:
张哲:我们的公司叫纸上绝知智能科技,公司主要有两个方向,一个是计算机视觉技术的研发,另一个方向是将计算机视觉技术应用到学习硬件里的各类应用。为什么做这个方向的创业,最早的灵感大概来自2017年的时候,我自己会看一些英文原版书,这就可能会有一个问题,就是书里会经常里有一些单词不认识,不查会觉得很难受,查了也会很难受。于是我就在想怎么解决这个问题。
从toB服务起步,计算机视觉技术赋能新的学习场景
在2013年左右的时候,有一个叫做Google Glass的产品,但是当时还不成熟。当时Google Glass的产品团队希望把Google Glass做到各种各样的应用里面去,可以说这种体验在理论上是非常好的。于是我也在想是否能够做一款眼镜。但是可以说这在当时是非常困难的,因为在这类产品中会涉及到比较多的核心技术,包括电池、散热、计算,在当时看都是很难的事情。
于是我们选择退而求其次,我们把场景再简化了一下,简化到能够实现这个类似Google Glass的功能,还能在某些特定场景使用的情况。那么,这种场景下需要什么东西呢?首先需要一个摄像头。为什么需要摄像头?因为摄像头能够看到真实世界里面的东西。第二个是需要一个计算芯片,因为这里面需要有很多的算法。第三个需要有一个显示屏幕。在当时,我们觉得最好的已经存在的硬件就是学习平板。在那个时候,学习平板已经有了一些年的发展历史了,整体的硬件水平还是不错的。
在2019年的时候,我们和很多合作伙伴进行合作开发的时候,也帮助学习平板做了一次比较大的升级。当时主流的学习平板,摄像头大概有两三百万的分辨率,芯片也是一般的芯片,因为他们的最主要作用就是播放视频、做PPT、讲课件,这些都是比较简单的操作。但是,当后来我们和合作伙伴合作开发手指点学项目之后,我们会把学习平板摄像头的分辨率提升到800万甚至1200万这样的水平。在芯片方面,也选用了比较前沿的一些芯片,甚至开始用一些带AI计算模组的芯片。
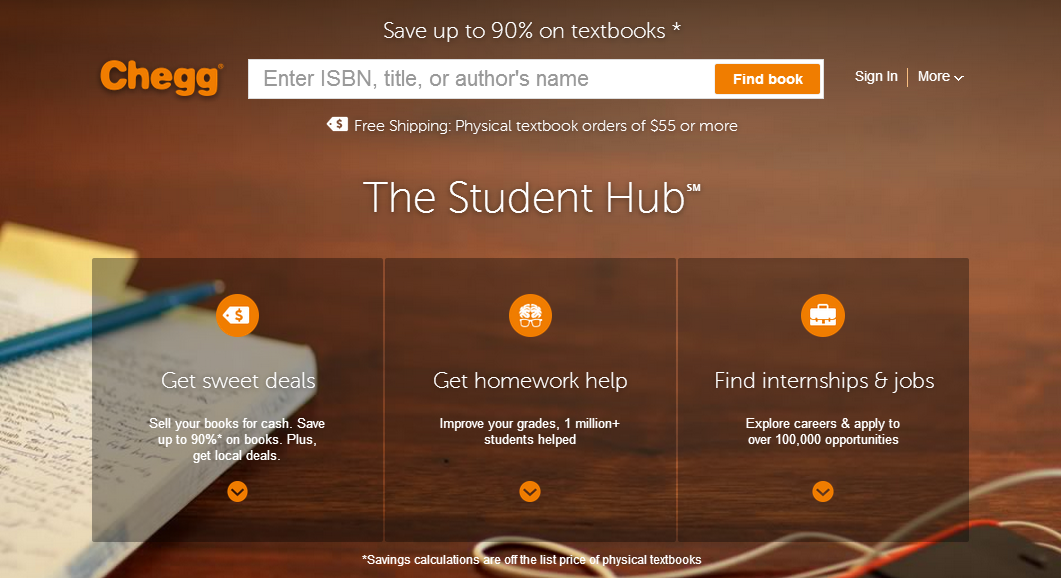
如上图左侧是一本绘本,这是实体的绘本,绘本上没有任何的感应设备,小朋友会用手指点一下绘本上的某个区域。如果点的是文字,这个时候我们就会把文字进行识别、翻译,通过屏幕的方式给小朋友讲解。但是如果点的是图像,就会连接到图像背后索引的内容。
但是在实际过程中,我们发现还是非常困难的。比如我们合作学习平板的机型种类非常多,基本上没有两个学习平板产品规格是一模一样的,包括平板里的摄像头也有很多讲究,比如分辨率、成像质量的差异等。除了硬件,还需要软件进行图像处理,但是每家学习平板的图像处理算法也都不太一样,而这会非常影响出图的效果。
最难把握的差异是用户的使用场景。在我们早期发展的时候没有做自己的硬件,我们都是服务客户的各种各样硬件,因此就遇到很大的挑战。在学习场景中,可能很多家长或者孩子会在光线很暗情况下看书,但是他们可能自己并不知道。还有的人家里的灯光很黄,拍出来的图像就会显模糊。还有的图像会有一些暗光甚至局部曝光。另外,有些摄像头会在不同的光线之下自动做白平衡,这会导致最后出来的图像差异非常大,这些都会导致最后算法的准确率很差。
最早我们刚上线的时候,准确率在很多时候大概只能到80%,这个体验是不太好的。因为我们本身用的是云服务,所以后台有很多真实使用的场景数据,三年多的时间积累了非常多的数据。在后来,我们进行了很多数据的标注和再训练,而且这个数据因为是用户的真实使用场景,结合模型的优化,到最后准确率就提高了非常多。我们在和客户的联合开发场景的过程,包括迭代的过程,让整个用户体验得到比较大的提升。
我个人的心得是其实AI(人工智能)技术的落地是非常难的,尤其是在早期阶段。首先落地必须得有场景,在没有落地的场景之前是无法获得数据的。这个时候大家就会用到一些小数据,或者接近实际场景的数据去做识别。但是当你的识别准确率没有达到效果的时候,客户一般是不会采用的。人工智能本身需要一个迭代的过程,很多领域相对风险要求比较高,比如说像自动驾驶、智慧医疗要求更高,他不可能容许拿真实的场景去做迭代。
所以大家感觉在某些领域的人工智能技术落地的速度会比较慢,原因就是在这个地方,它需要一个迭代,但是真实情况又不允许做迭代。因为我们做的是学习类硬件,学习硬件本身在早期不会产生特别重要的影响,包括用户和客户的容忍度还是比较高的,这也是我们觉得学习类硬件产业接下来发展速度会比较快的原因之一。

我们从2019年开始做这个技术赋能的方向,现在基本上这个技术已经成为了学习硬件的标配。今天,大家看到各种学习平板、学习灯、早教机肯定都会配套这样的功能。一个技术能够在两年时间里面,从零开始到最后基本全部成熟的过程,其实是非常快的。
我们最早做的是指尖定位技术,后来一直在深耕这个场景,那么,我们真正想打造的是什么样的东西呢?从我的个人理解来说,这其实是一种全新的交互形式,这种交互形式是打通了整个实体的学习场景和电子学习场景的过程。在以前,学习的场景基本上就两种:一种就是纯实体的,另外就是纯电子屏幕,但是这两者之间各有各的优势。实体的场景跟人的结合更近一些,比如看实体书书、写纸质作业等。但是在电子屏幕上看书还比较习惯,但是电子屏幕不太适合进行输出。但是电子屏幕有一个好处,它的背后会有非常海量的资源,包括各种学习资源、视频资源等,整个电子屏幕的交互形式也会更丰富。
所以我们在思考如何把这两个场景的优势结合起来。我们最早做的是手指点学,这项技术连通了实体世界和虚拟世界,这个虚拟世界就是电子屏幕。我们最早设想的形式就是类似iPhone的交互形式。
iPhone的交互形式其实就是点、滑、圈等等,其实全部都是手势里面的一些操作,通过手势的操作可以把平面里的东西全部识别到,然后抠取你的信息。所以我们在一开始做了多手势识别的技术,可以用手指在书上面进行点、滑、圈,也同样可以作出各种各样的手势。这个手势只要是在屏幕上面发生的,我们都可以记录手势的轨迹,根据手势的轨迹识别用户的意图。当时我们跟学习平板的公司一起定义了一些场景,比如说能不能手指在某个地方滑动一下就进行测评,在某个区域里面进行画圈后就可以进行课文的讲解。当然这个手势可以定义很多,在背后取决于我们如何跟场景结合起来。
在实际的实践过程中这是比较有挑战的。比如如何进行连续的姿势识别?我们利用的是设备的计算芯片,很难做到用非常大的GPU或者云端的计算力来支持连续的手势识别。利用设备的芯片一定会存在问题,就是速度的问题。我们的速度大概是1秒钟20次,精度也要求毫米级的精度,因为课本里面每行字之间的距离大概就是3-4mm,不会超过1cm的,所以必须要达到这个精度。如果这个精度达不到,手势识别就是不准的。在这个过程当中,我们需要非常多的合作伙伴包括MTK。借助他们的AI芯片并进行优化,同时,我们的学习平板客户也帮助我们采集了非常多的数据。
其他的挑战还包括如曲面干扰、手势识别分类的问题。我们采用了非常多的计算机视觉联合算法、联合硬件、联合数据的方式来优化这个过程,最后才能让这个场景在比较短的时间里落地。
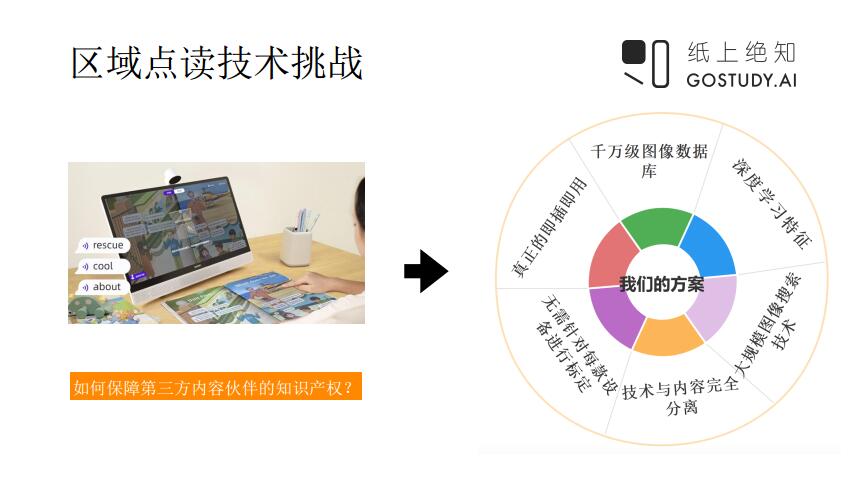
我们另外的一个场景是文字的场景,也可以说是图像的场景。图像的场景在硬件领域里面有一个词叫做“区域点读”。最早也是最典型的一个案例产品就是点读机和点读笔。现在我们完成把这个过程也变成了手势识别的过程。比如一个课本里包含了非常多的带有图像的区域,用户可能点到某个区域后就会自动地读出来这块区域相应的内容或者做一些教学,这是场景使用的情况。
那么在这个场景里最大的挑战是什么呢?这里面会涉及到非常多第三方的内容,比如每一家不管是硬件厂商还是培训体系,他们都会有自己的教研内容。比如K9的课本,像小学三年级的语文书,每一家的教学方法都不太一样,视频内容也不一样。核心问题就是如果这个技术和这个内容不能分离的话,就会出现很大的问题。到底这个内容放在谁那里?如果放在技术那里,内容就很容易被泄露。如何保障第三方内容伙伴知识产权?目前很多的技术方案做法,比如可以把内容数据放到云端,通过SDK去调用内容,可以在云端直接看到内容,包括图像内容、内容资源。这是比较大的版权和知识产权的问题。
这是我们AI生产的流程,首先是数据采集,有些数据是我们自己采集的,有些是和合作伙伴一起采集的,有些数据是用户真实使用的数据回流到我们服务器,重新进行采集和标注。
第二步是标注,针对我们的场景,最早使用了很多开源的标注工具,后来为了提升效率,为了覆盖更多的场景,我们自己开发了标注工具,所有标注的内容都是可以由我们自己调控的,效率也会变得比较高。
最后就是模型训练,我们目前用的比较多还是TensorFlow和PyTorch,但是在离线状态下PyTorch会比较困难一些,服务端可能还好一点。模型压缩是比较重要的,因为要跑到设备终端。我们现在服务的硬件数量接近300万台,对服务器和终端压力非常大。而且我们基本全部采用的是深度学习这一套模型框架,所以在服务端基本上全部用是的GPU,这对服务器压力是比较大的。所以我们必须要考虑到模型压缩,在模型训练完之后,一定要考虑到最后能承受多少,模型压缩可以压缩到什么程度。
目前我们的架构能够支持Linux、iOS和Android,现在也可以支持Unity这样的游戏框架。底层架构经过了好几期的迭代,主要是为了做游戏化的过程。
以上说的是我们在2019年成立之后主要做的to B赋能技术的大致范围。
如何将计算机视觉技术应用到家庭游戏化学习场景
我个人很早就关注了美国的OSMO这个教育游戏化产品,我觉得它的产品体验非常好,当然用户也觉得OSMO非常好。早些年国内有好几个厂家都尝试做过OSMO类似的产品,但是一直没有做起来。后来我们真正研究了一下,我们持续跟踪了OSMO多年的发展,他们产品的迭代是有一个明确方向的。
在目前的环境下,其实教育和学习不是一个东西,大家经常会把教育理解为培训,但是培训只是教育的一种形式,学习本身也有各种各样的形式。当然我们讲的比如说智能硬件的方式、交互的方式,就是一种很好的基础学习、家庭学习的场景。其实OSMO也是这样,它完全不依托于老师,是很好的自主学习的东西。
后来我又学习到一个东西叫做体验式学习。OSMO的整个使用过程是一种动手学习,也是属于体验式学习的一种。体验式学习就是要通过动手操作、互动、实际行动获得反馈,让用户收获一个抽象的概念。这个过程是在没有老师的情况之下进行学习的过程,就是探索、反馈、自己获得抽象的概念。这个形式也是未来比较重要的学习形式。

这是我列了一些OSMO的交互形式,非常丰富的。OSMO有两个核心的组件,一个是底座,一个是反射镜。反射镜可以把平板电脑的前置摄像头的角度调整到识别桌面的区域。所以当小朋友在桌面上进行操作的时候,交互形式还是非常聚焦在桌面这一块。
印度有一家叫PlayShifu的公司,他们做的产品的用户定位更加偏低幼龄一些,他们会做成更加实体的玩具,使用前置摄像头横放的角度。两家公司想法很接近,但是两家产品的目标用户人群和场景还是有些差异。OSMO交互方式更加适合教学,是带有教育意义的场景和东西,也比较倾向于做细粒度的操作,所以对孩子年龄段的要求相对来说会更高一点。OSMO可以和课本教材进行结合,所以在教育这个场景里面会用的广一点。
和大家介绍一下OSMO的产品挑战,这其中的挑战还是非常大的。
挑战一:OSMO主要支持的两种设备:iPad和Kindle Fire(亚马逊旗下的平板电脑),他们尝试过手机,后来放弃了。但是哪怕支持这两个设备也有很多的挑战。因为每个iPad的摄像头位置都不一样,角度也不一样、高度也不一样。OSMO有一个明显的特点,其所有的算力全部都放在终端,没有做云端计算力的东西,导致所有的算法模型最后要优化到iPad的设备都能够支持,这其实非常困难。
挑战二:环境关系也会很多,因为OSMO是toC的产品,卖给的用户你都不知道用户是在什么情况下使用OSMO。

挑战三:用户的年龄段。虽然OSMO产品用户标注的是5-12岁,但是是核心购买人群是3-8岁。这个年龄段里面用户操作很随意,如果大家真正观察小朋友拿着这个卡片做什么,他会把卡片抓一把往上面推。因为OSMO有识别区域,但是对于小朋友来说他不知道识别区。很多时候小朋友坐姿角度、身体遮挡等,也会让操作情况变得非常复杂。
挑战四:OSMO交互的东西比较多,有卡片、积木、绘本,对于它们来说每一种交互形式,以及最后实现的教学和游戏的形式也不一样,也就导致其算法不太一样。根据我们的了解,OSMO使用到的技术种类非常多,基本上计算机视觉里面能用到的技术都用到了。但是也很难做到用一项技术就解决所有的问题,这基本上不可能。OSMO的技术基本上是每一个新产品研发的同时就会做算法研发,所以他们的研发速度会比较慢。整个过程一定需要先做场景定义、教具研发,然后采数据、模型训练,一定会走这个流程。
在这个过程当中,如何能够把复杂的交互真正定义成一些模式,让这些东西达到可以复制的手段,这样的话就可以实现规模化,规模化之后这个产品才能商业化。
挑战五:因为OSMO做的全部是终端模型,因此要做非常多的模型压缩的问题。

在研究完OSMO产品遇到的挑战后,在2019年,我们也做了三款产品。我们也做了用户调研,我们发现有非常多的用户不同的反馈。我们做了三款产品,分别是跟绘本结合,和卡片结合,以及和画画本结合的场景。最近测试下来发现这三款产品各有各的特点。首先这种类型的产品我们推广过程当中发现一个问题,用户的沟通和教育成本非常高,因为中国没有类似的产品,家长对于这样的交互形式不理解。
但是我们在用户测试的时候发现一个特点,就是小朋友对于这种交互形式的体验和感觉非常好,他们对于这种交互形式的喜爱程度远超过任何实体的教具以及APP的交互形式。所以未来产品的发展方向,从教育场景来说家长是购买者,他们的想法非常重要。但是随着时间的推移,孩子喜欢的东西一定是会成为未来家长会买单的东西。
我们当时在做这个场景的时候,做了非常多算法研究。最早我们做画画游戏的时候,最早想对比一下两种算法,一个是传统的CV(计算机视觉)算法,一个是深度学习CV算法。后来我们使用了深度学习的算法,效果会好很多,这也是未来的方向。我们认为未来计算机视觉方向会以深度学习计算机视觉为主导。
随着深度学习的算法在这几年发展的非常快,包括芯片研究的进展很快。虽然现在成本还很高,包括算法工程师的招聘,人员还是很稀缺的,包括算力、芯片要求还是很高,但是从长远来看一定会下降。另外是规模化的问题,像这种应用一旦到了规模化之后,投入场景还是不错的。
Powered by Froala Editor