Google发布AIST++和FACT模型,可以根据不同的音乐背景生成3D舞蹈
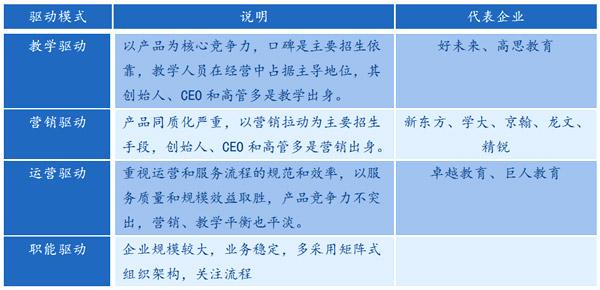
近日,在ICCV 2021上发表的“AI Choreographer: Music-Conditioned 3D Dance Generation with AIST++”中,Google公司提出了一种全注意力跨模态Transformer (Full-Attention Cross-modal Transformer,FACT) 模型可以模仿和理解舞蹈动作,甚至可以增强一个人的编舞能力。与此同时,Google公司还发布了一个大规模的多模态3D舞蹈动作数据集AIST++,其中包含1408个序列中5.2小时的3D舞蹈动作,涵盖10种舞蹈类型,每种类型都包括具有已知相机姿势的多视图视频。
通过对AIST++的广泛用户研究,Google发现FACT模型在定性和定量上都优于最近的最先进方法。
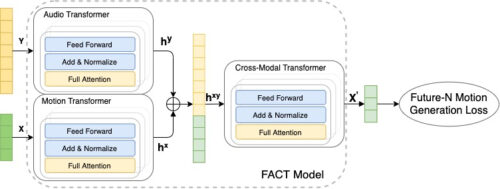
使用此数据,Google训练FACT模型以从音乐生成3D舞蹈。该模型首先使用单独的运动和音频转换器对种子运动和音频输入进行编码。然后将嵌入连接起来并发送到跨模态转换器,该转换器学习两种模态之间的对应关系并生成N个未来的运动序列。然后使用这些序列以自我监督的方式训练模型。所有三个变压器都是端到端共同学习的。在测试时,Google将此模型应用于自回归框架,其中预测的运动作为下一代步骤的输入。因此,FACT模型能够逐帧生成长距离舞蹈动作。
Google提出新颖的全注意力跨模态转换器 (FACT) 模型可以生成以音乐为条件的逼真3D舞蹈动作和新的3D舞蹈数据集AIST++。

Google从现有的AIST舞蹈视频数据库生成建议的3D运动数据集:一组带有音乐伴奏的舞蹈视频,但没有任何3D信息。AIST包含10种舞蹈流派:Old School(Break、Pop、Lock和Waack)和New School(Middle Hip-Hop、LA-style Hip-Hop、House、Krump、Street Jazz和Ballet Jazz)。虽然它包含舞者的多视图视频,但这些摄像机没有经过校准。
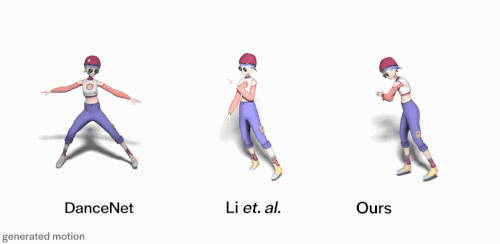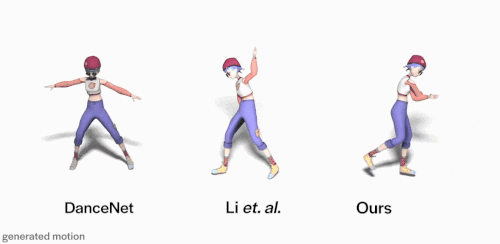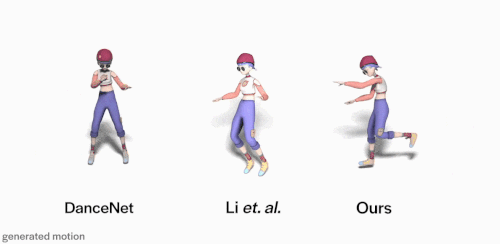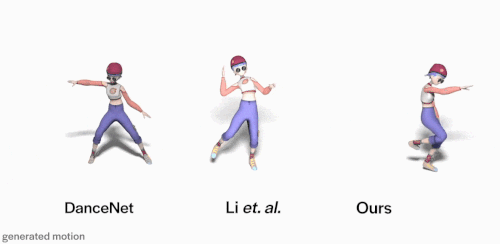
与DanceNet和Li et.al等先前方法相比。使用FACT模型生成的3D舞蹈(上图右)更逼真,并且与输入音乐的相关性更好。
AIST++建立在AIST舞蹈数据库之上,该数据库是一个未校准的多视图舞蹈视频集合。AIST++数据集设计用于作为运动生成和预测任务的基准。它也可能有利于其他任务,如2D/3D人体姿态预测。因为AIST是一个教学数据库,所以它记录了多个舞者按照相同的编舞为不同的音乐以不同的BPM,这是舞蹈中的常见做法。由于模型需要学习音频和运动之间的一对多映射,因此这在跨模态序列到序列生成中提出了独特的挑战。Google在AIST++上仔细构建了不重叠的训练和测试子集,以确保在子集之间既不共享编排也不共享音乐。
Powered by Froala Editor